As project managers, data experts, and program evaluators, our ability to convey information to stakeholders in a succinct and easy-to-understand format is critical. While formal written reports are sometimes needed to provide in-depth details about data and projects, concise communication tools are typically the most useful. In these instances, information experts must devise a quick and effective way to share their findings with decision makers and support the success of a project or policy (Otten, Cheng, & Drewnowski, 2015).
This often difficult process of selecting methodologies to convey technical knowledge to a non-technical audience is not a new dilemma; humans have been strategizing the best way to share complex data points for centuries, starting with cave drawings. For nearly 400 years, this study of data visualization has become embedded in academia and industry, spanning numerous fields and professions (Mackinlay & Winslow, n.d.).
In 1644, an early version of a line graph was devised by Michael Florent van Langren, an astronomer and cartographer from the Netherlands who was employed by the Spanish courts. This graphic is now considered to be the first statistical visualization (Friendly, 2006).
In 1786, William Playfair, a Scottish engineer, published one of the first books on data visualization, Commercial and Political Atlas, to present trade-related data in England. In the book and his following work, Playfair introduced numerous ways to display data. Many of his strategies, including the Pie Chart, remain prevalent today and Playfair is often considered to be the “father of statistical presentation” (Mackinlay & Winslow, n.d.).
Subsequently in the 1800s, statistical visualizations increased in popularity and usage ranging from the epidemiological visualizations by British physician Dr. Jon Snow in 1855 and British statistician and founder of modern nursing, Florence Nightingale in 1856, the historical representation of Napoleon’s loss of 1812 by French civil engineer Charles Minard in 1869, and the demographic work by American sociologist W.E.B. Du Bois in the late 1800s-early 1900s (Mackinlay & Winslow, n.d., Andrews, 2022, Mansky, 2018).
From the 1900s to the present, researchers across disciplines have continued examining the best ways to present specialized knowledge to general audiences. Experts such as Edward Tufte, Stephanie Evergreen, Joel Best, Cole Nussbaumer Knaflic, David McCandless, Nathan Yau, Talithia Williams, members of the Data Visualization Society and others have dedicated their careers to data visualization and literacy and provide great insights on how to utilize modern technologies to make complex topics easier to understand with numbers and visuals.
One type of data visualization that has particularly grown in popularity over the past few years are infographics. Albers (2014) defines the term infographic as “a web-based image that takes a large amount of information in text or numerical form and condenses it into a combination of images and text with a goal of making the information presentable and digestible to an audience”. Further, “[w]hile not appropriate or useful for all types of content, infographics provide context by using visuals to show relationships in data, anatomy, hierarchy, chronology, and geography. Communicating relationships are at the heart of communicating complex information and infographics excel at communicating that aspect.” (Albers, 2015). The primary types of infographics are data graphics, maps, and diagrams (Otten, Cheng, & Drewnowski, 2015).
To see infographics in action, check out the following video on the 100 People Project as a great example of how data communicators can transform really large amounts of data into simple visuals:
In addition to pictorial infographics, well-designed maps are an excellent visualization tool to present geographic project data. Maps are particularly critical to helping stakeholders identify what areas of their target region are most in need.
The video below provides an introduction to the usage of choropleth maps for this purpose:
This week we will be combining the powers of the R package ggplot2 with patchwork and ggiraph to create our infographics and interactive map.
If you would like an overview of these packages, you can view the following videos:
Also, to read further about the history of data visualization as well as the specific data visualization types mentioned in the videos above check out the links here:
Infographics And Public Policy: Using Data Visualization To Convey Complex Information by Jennifer J. Otten, Karen Cheng, and Adam Drewnowski (2015) download
Designing Great Visualizations Whitepaper by Jock D. Mackinlay with Kevin Winslow (n.d.) download
A Brief History of Data Visualization by Michael Friendly (2006): download
How Florence Nightingale Changed Data Visualization Forever by RJ Andrews (2022): download
W.E.B. Du Bois’ Visionary Infographics Come Together for the First Time in Full Color by Jackie Mansky (2018): download
Infographics: Horrid Chartjunk or Quality Communication by Michael J. Albers (2014): download
Infographics and Communicating Complex Information by Michael J. Albers (2015): download
Visualizations That Really Work by Scott Berinato (2016): download
Now that we’ve explored pictorial waffle chart infographics and choropleth maps as tools for project data presentation, in this lab we will practice creating our own visuals to analyze our CDC Social Vulnerability Index for our divisions of interest.
Library
To begin, we will need to install a few new packages and load some packages that we’ve previously installed:
For this lab we will be storing the output of our analysis in a sub-folder called imgs. If no one on your team has created the labs/wk03/imgs folder, go ahead and add it now.
Functions and Constant Variables
Recall in Lab 02 that we created functions to process our data throughout the duration of the project. You should have these four functions in your project_data_steps.R:
fips_region_assignment()
rank_variables()
svi_theme_variables()
svi_theme_flags()
Next, you will want to add the following four (4) functions to your project_data_steps.R file to complete this lab:
The first function combines our previous functions into one singular function that makes it easier to process our data in one step and the second allows us to merge our 2010 and 2020 dataframes into one:
Code
# Process data ----load_svi_data<-function(df, rank_by="national", location=NULL, state_abbr=NULL, percentile=.90){df<-fips_region_assignment(df)df<-rank_variables(df, rank_by, location, state_abbr)df<-svi_theme_variables(df)df<-svi_theme_flags(df, percentile)return(df)}# Merge SVI data periods ----merge_svi_data<-function(df10, df20){joint_tracts<-dplyr::intersect(df10$GEOID_2010_trt, df20$GEOID_2010_trt)%>%tibble()colnames(joint_tracts)<-"GEOID_2010_trt"svi_merged<-left_join(joint_tracts, df10, join_by("GEOID_2010_trt"=="GEOID_2010_trt"))df20<-df20%>%select(!c(colnames(df20)[2:11]))svi_merged<-left_join(svi_merged, df20, join_by("GEOID_2010_trt"=="GEOID_2010_trt"))colnames(svi_merged)<-str_replace(colnames(svi_merged), "\\.x", "_10")colnames(svi_merged)<-str_replace(colnames(svi_merged), "\\.y", "_20")return(svi_merged)}
The following two functions will sum up percentages of our SVI variables for our locations of interest:
Code
# Calculate SVI variable percentages ----svi_percentages10<-function(df, division_name){df_out<-df%>%filter(!is.na(ET_INSURSTATUS_12))%>%summarise( division =division_name, year =2010, `pct in poverty` =round(sum(E_POV150_10)/sum(ET_POVSTATUS_10)*100), `pct not in poverty` =round(((sum(ET_POVSTATUS_10)-sum(E_POV150_10))/sum(ET_POVSTATUS_10))*100), `pct unemployed` =round(sum(E_UNEMP_10)/sum(ET_EMPSTATUS_10)*100), `pct employed` =round(((sum(ET_EMPSTATUS_10)-sum(E_UNEMP_10))/sum(ET_EMPSTATUS_10))*100), `pct housing cost-burdened` =round(sum(E_HBURD_10)/sum(ET_HOUSINGCOST_10)*100), `pct not housing cost-burdened` =round(((sum(ET_HOUSINGCOST_10)-sum(E_HBURD_10))/sum(ET_HOUSINGCOST_10))*100), `pct adults without high school diploma` =round(sum(E_NOHSDP_10)/sum(ET_EDSTATUS_10)*100), `pct adults with high school diploma` =round(((sum(ET_EDSTATUS_10)-sum(E_NOHSDP_10))/sum(ET_EDSTATUS_10))*100), `pct age 17 & under` =round(sum(E_AGE17_10)/sum(E_TOTPOP_10)*100), `pct age 18-64` =round((sum(E_TOTPOP_10)/sum(E_TOTPOP_10)*100)-(sum(round(sum(E_AGE17_10)/sum(E_TOTPOP_10)*100), round(sum(E_AGE65_10)/sum(E_TOTPOP_10)*100)))), `pct age 65+` =round(sum(E_AGE65_10)/sum(E_TOTPOP_10)*100), `pct single parent families` =round(sum(E_SNGPNT_10)/sum(ET_FAMILIES_10)*100), `pct other families` =round(((sum(ET_FAMILIES_10)-sum(E_SNGPNT_10))/sum(ET_FAMILIES_10))*100), `pct limited English speakers` =round(sum(E_LIMENG_10)/sum(ET_POPAGE5UP_10)*100), `pct proficient English speakers` =round(((sum(ET_POPAGE5UP_10)-sum(E_LIMENG_10))/sum(ET_POPAGE5UP_10))*100), `pct Minority race/ethnicity` =round(sum(E_MINRTY_10)/sum(ET_POPETHRACE_10)*100), `pct Non-Hispanic White race/ethnicity` =round(((sum(ET_POPETHRACE_10)-sum(E_MINRTY_10))/sum(ET_POPETHRACE_10))*100), `pct in multi-unit housing` =round(sum(E_MUNIT_10)/sum(E_STRHU_10)*100), `pct in mobile housing` =round(sum(E_MOBILE_10)/sum(E_STRHU_10)*100), `pct in other housing` =(100-sum(round(sum(E_MUNIT_10)/sum(E_STRHU_10)*100), round(sum(E_MOBILE_10)/sum(E_STRHU_10)*100))), `pct in crowded living spaces` =round(sum(E_CROWD_10)/sum(ET_OCCUPANTS_10)*100), `pct in non-crowded living spaces` =round(((sum(ET_OCCUPANTS_10)-sum(E_CROWD_10))/sum(ET_OCCUPANTS_10))*100), `pct with no vehicle access` =round(sum(E_NOVEH_10)/sum(ET_KNOWNVEH_10)*100), `pct with vehicle access` =round(((sum(ET_KNOWNVEH_10)-sum(E_NOVEH_10))/sum(ET_KNOWNVEH_10))*100), `pct in group living quarters` =round(sum(E_GROUPQ_10)/sum(ET_HHTYPE_10)*100), `pct not in group living quarters` =round(((sum(ET_HHTYPE_10)-sum(E_GROUPQ_10))/sum(ET_HHTYPE_10))*100), `pct without health insurance` =round(sum(E_UNINSUR_12)/sum(ET_INSURSTATUS_12)*100), `pct with health insurance` =round(((sum(ET_INSURSTATUS_12)-sum(E_UNINSUR_12))/sum(ET_INSURSTATUS_12))*100), `pct disabled civilians` =round(sum(E_DISABL_12)/sum(ET_DISABLSTATUS_12)*100), `pct not disabled civilians` =round(((sum(ET_DISABLSTATUS_12)-sum(E_DISABL_12))/sum(ET_DISABLSTATUS_12))*100))return(df_out)}svi_percentages20<-function(df, division_name){df_out<-df%>%summarise( division =division_name, year =2020, `pct in poverty` =round(sum(E_POV150_20)/sum(ET_POVSTATUS_20)*100), `pct not in poverty` =round(((sum(ET_POVSTATUS_20)-sum(E_POV150_20))/sum(ET_POVSTATUS_20))*100), `pct unemployed` =round(sum(E_UNEMP_20)/sum(ET_EMPSTATUS_20)*100), `pct employed` =round(((sum(ET_EMPSTATUS_20)-sum(E_UNEMP_20))/sum(ET_EMPSTATUS_20))*100), `pct housing cost-burdened` =round(sum(E_HBURD_20)/sum(ET_HOUSINGCOST_20)*100), `pct not housing cost-burdened` =round(((sum(ET_HOUSINGCOST_20)-sum(E_HBURD_20))/sum(ET_HOUSINGCOST_20))*100), `pct adults without high school diploma` =round(sum(E_NOHSDP_20)/sum(ET_EDSTATUS_20)*100), `pct adults with high school diploma` =round(((sum(ET_EDSTATUS_20)-sum(E_NOHSDP_20))/sum(ET_EDSTATUS_20))*100), `pct age 17 & under` =round(sum(E_AGE17_20)/sum(E_TOTPOP_20)*100), `pct age 18-64` =round((sum(E_TOTPOP_20)/sum(E_TOTPOP_20)*100)-(sum(round(sum(E_AGE17_20)/sum(E_TOTPOP_20)*100), round(sum(E_AGE65_20)/sum(E_TOTPOP_20)*100)))), `pct age 65+` =round(sum(E_AGE65_20)/sum(E_TOTPOP_20)*100), `pct single parent families` =round(sum(E_SNGPNT_20)/sum(ET_FAMILIES_20)*100), `pct other families` =round(((sum(ET_FAMILIES_20)-sum(E_SNGPNT_20))/sum(ET_FAMILIES_20))*100), `pct limited English speakers` =round(sum(E_LIMENG_20)/sum(ET_POPAGE5UP_20)*100), `pct proficient English speakers` =round(((sum(ET_POPAGE5UP_20)-sum(E_LIMENG_20))/sum(ET_POPAGE5UP_20))*100), `pct Minority race/ethnicity` =round(sum(E_MINRTY_20)/sum(ET_POPETHRACE_20)*100), `pct Non-Hispanic White race/ethnicity` =round(((sum(ET_POPETHRACE_20)-sum(E_MINRTY_20))/sum(ET_POPETHRACE_20))*100), `pct in multi-unit housing` =round(sum(E_MUNIT_20)/sum(E_STRHU_20)*100), `pct in mobile housing` =round(sum(E_MOBILE_20)/sum(E_STRHU_20)*100), `pct in other housing` =(100-sum(round(sum(E_MUNIT_20)/sum(E_STRHU_20)*100), round(sum(E_MOBILE_20)/sum(E_STRHU_20)*100))), `pct in crowded living spaces` =round(sum(E_CROWD_20)/sum(ET_OCCUPANTS_20)*100), `pct in non-crowded living spaces` =round(((sum(ET_OCCUPANTS_20)-sum(E_CROWD_20))/sum(ET_OCCUPANTS_20))*100), `pct with no vehicle access` =round(sum(E_NOVEH_20)/sum(ET_KNOWNVEH_20)*100), `pct with vehicle access` =round(((sum(ET_KNOWNVEH_20)-sum(E_NOVEH_20))/sum(ET_KNOWNVEH_20))*100), `pct in group living quarters` =round(sum(E_GROUPQ_20)/sum(ET_HHTYPE_20)*100), `pct not in group living quarters` =round(((sum(ET_HHTYPE_20)-sum(E_GROUPQ_20))/sum(ET_HHTYPE_20))*100), `pct without health insurance` =round(sum(E_UNINSUR_20)/sum(ET_INSURSTATUS_20)*100), `pct with health insurance` =round(((sum(ET_INSURSTATUS_20)-sum(E_UNINSUR_20))/sum(ET_INSURSTATUS_20))*100), `pct disabled civilians` =round(sum(E_DISABL_20)/sum(ET_DISABLSTATUS_20)*100), `pct not disabled civilians` =round(((sum(ET_DISABLSTATUS_20)-sum(E_DISABL_20))/sum(ET_DISABLSTATUS_20))*100))return(df_out)}
Next we need to import our functions and constants from our project_data_steps.R file. Remember, your file should have your initials/name at the end to avoid confusion with your teammates. For example, in a shared repo my file name would be project_data_steps_CS.R or project_data_steps_courtney.R
Recall that we should use the here::here() function for relative file paths. We also can use double colons :: to indicate both the specific library and function name we want to use to avoid any overriding.
Code
import::here("fips_census_regions","load_svi_data","merge_svi_data","census_division","svi_percentages10","svi_percentages20",# notice the use of here::here() that points to the .R file# where all these R objects are created .from =here::here("analysis/project_data_steps.R"), .character_only =TRUE)
Check that your census division variable loaded properly and reflects your division of interest:
Code
census_division
[1] "Middle Atlantic Division"
Data
Finally, we can load up our data sets and process them with our functions to create data sets on a national and divisional level for 2010 and 2020.
Note
Note that we will want to flag our SVI indicators at or above the 75th percentile. For the divisional data we will also want to utilize the rank_by and location parameters to limit to our division of interest.
Code
# Load data from raw foldersvi_2010<-readRDS(here::here("data/raw/Census_Data_SVI/svi_2010_trt10.rds"))svi_2020<-readRDS(here::here("data/raw/Census_Data_SVI/svi_2020_trt10.rds"))
Next, we want to check that our functions are behaving as expected and have filtered our data sets to include all divisions and states on the national level and only our division/states of interest on the divisional level:
[1] "East South Central Division" "Pacific Division"
[3] "Mountain Division" "West South Central Division"
[5] "New England Division" "South Atlantic Division"
[7] "East North Central Division" "West North Central Division"
[9] "Middle Atlantic Division"
[1] "East South Central Division" "Pacific Division"
[3] "Mountain Division" "West South Central Division"
[5] "New England Division" "South Atlantic Division"
[7] "East North Central Division" "West North Central Division"
[9] "Middle Atlantic Division"
Now that we have our data loaded properly, we need to process it further to find the percentages of our Social Vulnerability Indices nationally and divisionally for 2010 and 2020:
[1] "division"
[2] "year"
[3] "pct in poverty"
[4] "pct not in poverty"
[5] "pct unemployed"
[6] "pct employed"
[7] "pct housing cost-burdened"
[8] "pct not housing cost-burdened"
[9] "pct adults without high school diploma"
[10] "pct adults with high school diploma"
[11] "pct age 17 & under"
[12] "pct age 18-64"
[13] "pct age 65+"
[14] "pct single parent families"
[15] "pct other families"
[16] "pct limited English speakers"
[17] "pct proficient English speakers"
[18] "pct Minority race/ethnicity"
[19] "pct Non-Hispanic White race/ethnicity"
[20] "pct in multi-unit housing"
[21] "pct in mobile housing"
[22] "pct in other housing"
[23] "pct in crowded living spaces"
[24] "pct in non-crowded living spaces"
[25] "pct with no vehicle access"
[26] "pct with vehicle access"
[27] "pct in group living quarters"
[28] "pct not in group living quarters"
[29] "pct without health insurance"
[30] "pct with health insurance"
[31] "pct disabled civilians"
[32] "pct not disabled civilians"
Note about Group Quarters definition:
The Census Bureau classifies all people not living in housing units as living in group quarters. A group quarters is a place where people live or stay, in a group living arrangement, that is owned or managed by an entity or organization providing housing and/or services for the residents.
This is not a typical household-type living arrangement. These services may include custodial or medical care as well as other types of assistance, and residency is commonly restricted to those receiving these services. People living in group quarters are usually not related to each other.
Group quarters include such places as college residence halls, residential treatment centers, skilled nursing facilities, group homes, military barracks, correctional facilities, and workers’ dormitories.
Now that we have our data loaded, we can begin creating our visualizations. Note that while all steps are presented here for the tutorial, in your actual report files, you will just want to display the infographics and NOT all the steps to create them. An example final file will be linked at the end of the report.
Waffle Charts
First, we will create our waffle charts. While waffle charts are not a visualization that comes pre-loaded with ggplot2, several R programmers have worked to devise methodologies to create these charts with icons from FontAwesome.
We will be modifying code from the following resources to create our charts:
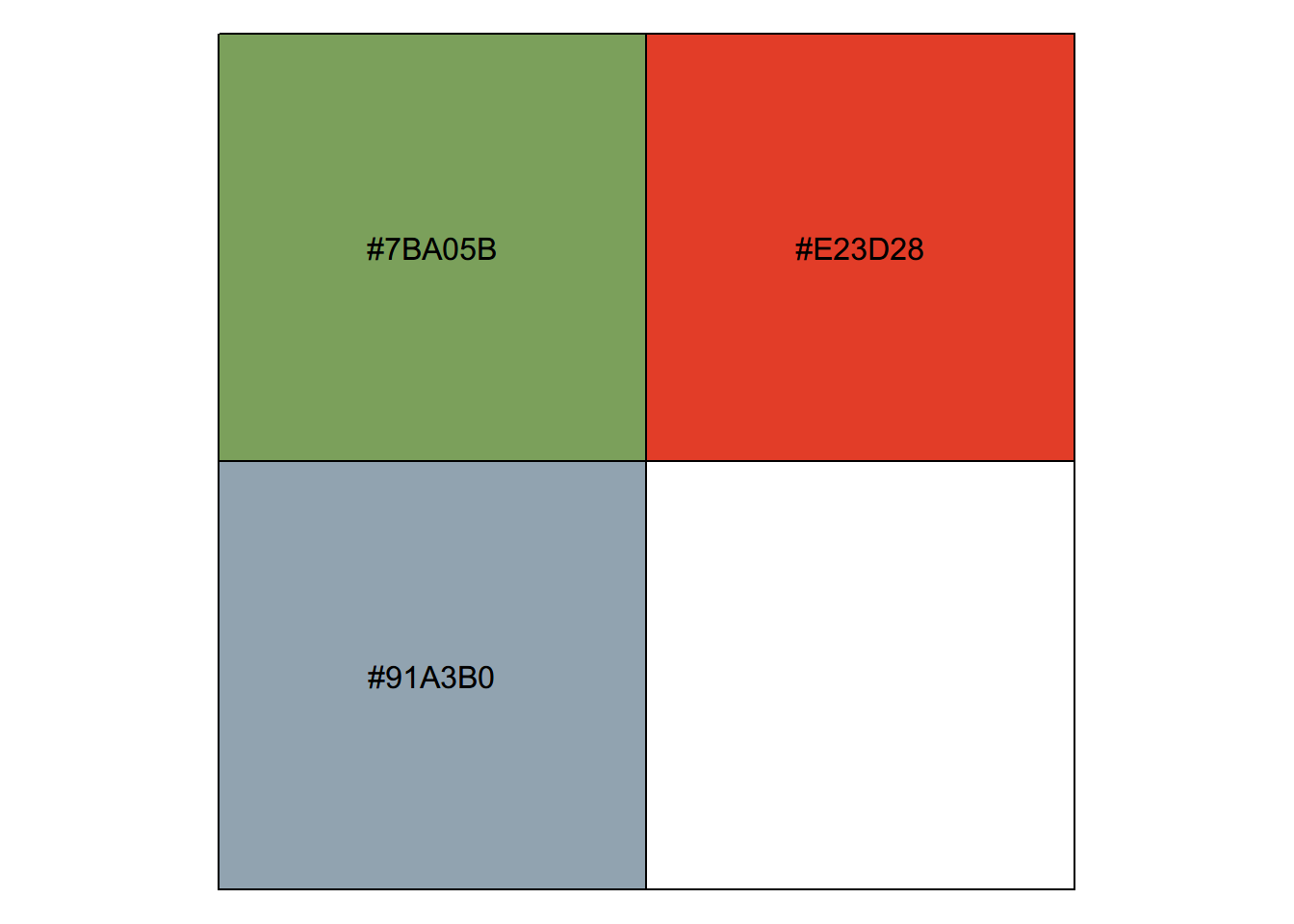
Before we can plot our graphs, we first need to create color palettes for our two, three, and four category variables. The following colors were selected from Coolors: https://coolors.co/colors. Feel free to select your own colors of interest, but note that you will want to have one color in each group as a shade of gray/tan to contrast with your categories of interest.
Code
# Palette for SVI variables with only two categoriesone_color_palette<-c("#960018", "#91A3B0")scales::show_col(one_color_palette)
Code
# Palette for SVI variables with three categoriestwo_color_palette<-c("#7BA05B", "#E23D28", "#91A3B0")scales::show_col(two_color_palette)
Code
# Palette for SVI variables with four categoriesthree_color_palette<-c("#003262", "#91A3B0" , "#960018", "#ED9121")scales::show_col(three_color_palette)
Select Font Awesome icons for pictorial charts
Now that we have our color palettes created, we need to select the Font Awesome icons we want to use.
In order to do this we need to follow three steps:
Identify the unicode value for the icons. We can find this on the top right corner of the icon page on the FontAwesome website. See screenshot below:
Alt-text: Screenshot of GitHub icon on FontAwesome page with unicode enclosed in red box. Screenshot source
Add \u to the font of the unicode value and save it to a variable for R in your project_data_steps.R file.
If you do not already have the FontAwesome icons downloaded, you will need to download the Free for Web icons from the download section of the FontAwesome website https://fontawesome.com/download. Note: for our class, you already have the fonts downloaded in your team repo in the resources folder so you do not need to download anything.
Selected icons:
Person icon f183:
House icon f015:
Car icon f1b9:
Parent icon e53a:
Health icon f80d :
Group Quarter icon f1ad:
Code
# Don't forget to save FontAwesome variables to project_data_steps.R, remember to add \u to indicate this is unicode for ggplot2.person_icon="\uf183"house_icon="\uf015"car_icon="\uf1b9"parent_icon="\ue53a"health_icon="\uf80d"groupqtr_icon="\uf1ad"
Create Waffle Charts graphing function
Next, we will create a function to actually plot our waffle charts. The function will create four (4) visuals: a 2010 divisional waffle chart, a 2010 national waffle chart, a 2020 divisional waffle chart, and a 2020 national waffle chart.
For our function we’ll have the following inputs:
svi_pcts: data frame that contains SVI pcts nationally and divisionally for 2010 and 2020
var_search: keyword to search data frame columns for all columns relevant to the topic of interest
fa_icon: the selected icon to represent the waffle chart for our variable of interest
filter_year1: the first year of the two time periods, for our study it’s 2010
title_label_div_year1: the title for year1 (2010) division infographic
title_label_usa_year1: the title for year1 (2010) national infographic
filter_year2: the second year of the two time periods, for our study it’s 2020
title_label_div_year2: the title for year2 (2020) division infographic
title_label_usa_year2: the title for year2 (2020) national infographic
census_division: the name of the census division we want to filter our data to select
Now we can construct our function (REMEMBER: We will want to place this custom function with our others in the project_data_steps.R file, not directly in our .RMD file):
Code
waffle_charts<-function(svi_pcts, var_search, fa_icon, filter_year1, title_label_div_year1, title_label_usa_year1, filter_year2, title_label_div_year2, title_label_usa_year2, census_division){# Filter data to find columns by var_search keyword, select all columns with keyword, count number of columnscols<-tolower(colnames(svi_pcts))%>%str_detect(tolower(var_search))cols_select<-colnames(svi_pcts)[cols]n_cols_select<-length(cols_select)# Set color palette for visualizationsone_color_palette<-c("#960018", "#91A3B0")two_color_palette<-c("#7BA05B", "#E23D28", "#91A3B0")three_color_palette<-c("#003262", "#91A3B0" , "#960018", "#ED9121")if(n_cols_select==2){color_palette<-one_color_palette}elseif(n_cols_select==3&var_search!="age"){color_palette<-two_color_palette}else{color_palette<-three_color_palette}# Division Year1svidf<-svi_pcts%>%filter(division==census_division&year==filter_year1)%>%select(all_of(cols_select))# Create 10x10 grid and then display variables of interests' categories the number of times they appear in data to total to 100# For example, for group quarters, the code repeats group quarters 2 times and non-group quarters 98 times# for 2020 national data for plottingdf<-expand.grid(y =1:10, x =1:10)df$category<-factor(rep(names(svidf),svidf), levels=names(svidf))# Pull in downloaded fontawesome font to display font awesome icons in graphicfont_add(family ="FontAwesome", regular =here::here("resources/fontawesome-free-6.5.1-web/webfonts/fa-solid-900.ttf"))showtext_auto(T)p1<-ggplot(df, aes(x =y, y =x, color=category))+geom_text(label =fa_icon, family ='FontAwesome', size =6)+scale_color_manual(values =color_palette)+coord_fixed(ratio =1)+scale_x_continuous(expand =c(0.1, 0.1))+scale_y_continuous(expand =c(0.1, 0.1),trans ='reverse')+theme( panel.background =element_blank(), plot.title =element_text(size =22, hjust =0), axis.text =element_blank(), axis.title =element_blank(), axis.ticks =element_blank(), legend.title =element_blank(), legend.position ="right", legend.key =element_rect(colour =NA, fill =NA), legend.key.size =unit(1.5, "cm"), legend.text =element_text(size =rel(1.2)))+guides(fill =guide_legend(byrow =TRUE))+labs(title=title_label_div_year1)# Division Year2svidf<-svi_pcts%>%filter(division==census_division&year==filter_year2)%>%select(all_of(cols_select))# Create 10x10 grid and then display variables of interests' categories the number of times they appear in data to total to 100# For example, for group quarters, the code repeats group quarters 2 times and non-group quarters 98 times# for 2020 national data for plottingdf<-expand.grid(y =1:10, x =1:10)df$category<-factor(rep(names(svidf),svidf), levels=names(svidf))# Pull in downloaded fontawesome font to display font awesome icons in graphicfont_add(family ="FontAwesome", regular =here::here("resources/fontawesome-free-6.5.1-web/webfonts/fa-solid-900.ttf"))showtext_auto(T)p2<-ggplot(df, aes(x =y, y =x, color=category))+geom_text(label =fa_icon, family ='FontAwesome', size =6)+scale_color_manual(values =color_palette)+coord_fixed(ratio =1)+scale_x_continuous(expand =c(0.1, 0.1))+scale_y_continuous(expand =c(0.1, 0.1),trans ='reverse')+theme( panel.background =element_blank(), plot.title =element_text(size =22, hjust =0), axis.text =element_blank(), axis.title =element_blank(), axis.ticks =element_blank(), legend.title =element_blank(), legend.position ="right", legend.key =element_rect(colour =NA, fill =NA), legend.key.size =unit(1.5, "cm"), legend.text =element_text(size =rel(1.2)))+guides(fill =guide_legend(byrow =TRUE))+labs(title=title_label_div_year2)# National Year1svidf<-svi_pcts%>%filter(division!=census_division&year==filter_year1)%>%select(all_of(cols_select))# Create 10x10 grid and then display variables of interests' categories the number of times they appear in data to total to 100# For example, for group quarters, the code repeats group quarters 2 times and non-group quarters 98 times# for 2020 national data for plottingdf<-expand.grid(y =1:10, x =1:10)df$category<-factor(rep(names(svidf),svidf), levels=names(svidf))# Pull in downloaded fontawesome font to display font awesome icons in graphicfont_add(family ="FontAwesome", regular =here::here("resources/fontawesome-free-6.5.1-web/webfonts/fa-solid-900.ttf"))showtext_auto(T)p3<-ggplot(df, aes(x =y, y =x, color=category))+geom_text(label =fa_icon, family ='FontAwesome', size =6)+scale_color_manual(values =color_palette)+coord_fixed(ratio =1)+scale_x_continuous(expand =c(0.1, 0.1))+scale_y_continuous(expand =c(0.1, 0.1),trans ='reverse')+theme( panel.background =element_blank(), plot.title =element_text(size =22, hjust =0), axis.text =element_blank(), axis.title =element_blank(), axis.ticks =element_blank(), legend.title =element_blank(), legend.position ="right", legend.key =element_rect(colour =NA, fill =NA), legend.key.size =unit(1.5, "cm"), legend.text =element_text(size =rel(1.2)))+guides(fill =guide_legend(byrow =TRUE))+labs(title=title_label_usa_year1)# National Year2svidf<-svi_pcts%>%filter(division!=census_division&year==filter_year2)%>%select(all_of(cols_select))# Create 10x10 grid and then display variables of interests' categories the number of times they appear in data to total to 100# For example, for group quarters, the code repeats group quarters 2 times and non-group quarters 98 times# for 2020 national data for plottingdf<-expand.grid(y =1:10, x =1:10)df$category<-factor(rep(names(svidf),svidf), levels=names(svidf))# Pull in downloaded fontawesome font to display font awesome icons in graphicfont_add(family ="FontAwesome", regular =here::here("resources/fontawesome-free-6.5.1-web/webfonts/fa-solid-900.ttf"))showtext_auto(T)p4<-ggplot(df, aes(x =y, y =x, color=category))+geom_text(label =fa_icon, family ='FontAwesome', size =6)+scale_color_manual(values =color_palette)+coord_fixed(ratio =1)+scale_x_continuous(expand =c(0.1, 0.1))+scale_y_continuous(expand =c(0.1, 0.1),trans ='reverse')+theme( panel.background =element_blank(), plot.title =element_text(size =22, hjust =0), axis.text =element_blank(), axis.title =element_blank(), axis.ticks =element_blank(), legend.title =element_blank(), legend.position ="right", legend.key =element_rect(colour =NA, fill =NA), legend.key.size =unit(1.5, "cm"), legend.text =element_text(size =rel(1.2)))+guides(fill =guide_legend(byrow =TRUE))+labs(title=title_label_usa_year2)# Create list of all plotsplotlist=list(p1, p2, p3, p4)return(plotlist)}
To get a visual of the grid the code is creating, let’s take a peek:
Code
# For our example we'll search for our health variablesvar_search<-"health"cols<-tolower(colnames(svi_pcts))%>%str_detect(tolower(var_search))cols_select<-colnames(svi_pcts)[cols]n_cols_select<-length(cols_select)
Code
# View selected columns for health:cols_select
[1] "pct without health insurance" "pct with health insurance"
Code
# View number of selected columns for health:n_cols_select
[1] 2
Code
# Filter data by division and year, select columns of interest:svidf<-svi_pcts%>%filter(division==census_division&year==2010)%>%select(all_of(cols_select))# View datasvidf
# A tibble: 1 × 2
`pct without health insurance` `pct with health insurance`
<dbl> <dbl>
1 11 89
# View names of df that will serve as labelsnames(svidf)
[1] "pct without health insurance" "pct with health insurance"
Code
# Repeat the names by the number if times they're in the dfrep(names(svidf),svidf)
[1] "pct without health insurance" "pct without health insurance"
[3] "pct without health insurance" "pct without health insurance"
[5] "pct without health insurance" "pct without health insurance"
[7] "pct without health insurance" "pct without health insurance"
[9] "pct without health insurance" "pct without health insurance"
[11] "pct without health insurance" "pct with health insurance"
[13] "pct with health insurance" "pct with health insurance"
[15] "pct with health insurance" "pct with health insurance"
[17] "pct with health insurance" "pct with health insurance"
[19] "pct with health insurance" "pct with health insurance"
[21] "pct with health insurance" "pct with health insurance"
[23] "pct with health insurance" "pct with health insurance"
[25] "pct with health insurance" "pct with health insurance"
[27] "pct with health insurance" "pct with health insurance"
[29] "pct with health insurance" "pct with health insurance"
[31] "pct with health insurance" "pct with health insurance"
[33] "pct with health insurance" "pct with health insurance"
[35] "pct with health insurance" "pct with health insurance"
[37] "pct with health insurance" "pct with health insurance"
[39] "pct with health insurance" "pct with health insurance"
[41] "pct with health insurance" "pct with health insurance"
[43] "pct with health insurance" "pct with health insurance"
[45] "pct with health insurance" "pct with health insurance"
[47] "pct with health insurance" "pct with health insurance"
[49] "pct with health insurance" "pct with health insurance"
[51] "pct with health insurance" "pct with health insurance"
[53] "pct with health insurance" "pct with health insurance"
[55] "pct with health insurance" "pct with health insurance"
[57] "pct with health insurance" "pct with health insurance"
[59] "pct with health insurance" "pct with health insurance"
[61] "pct with health insurance" "pct with health insurance"
[63] "pct with health insurance" "pct with health insurance"
[65] "pct with health insurance" "pct with health insurance"
[67] "pct with health insurance" "pct with health insurance"
[69] "pct with health insurance" "pct with health insurance"
[71] "pct with health insurance" "pct with health insurance"
[73] "pct with health insurance" "pct with health insurance"
[75] "pct with health insurance" "pct with health insurance"
[77] "pct with health insurance" "pct with health insurance"
[79] "pct with health insurance" "pct with health insurance"
[81] "pct with health insurance" "pct with health insurance"
[83] "pct with health insurance" "pct with health insurance"
[85] "pct with health insurance" "pct with health insurance"
[87] "pct with health insurance" "pct with health insurance"
[89] "pct with health insurance" "pct with health insurance"
[91] "pct with health insurance" "pct with health insurance"
[93] "pct with health insurance" "pct with health insurance"
[95] "pct with health insurance" "pct with health insurance"
[97] "pct with health insurance" "pct with health insurance"
[99] "pct with health insurance" "pct with health insurance"
Code
# Add category to dfdf$category<-factor(rep(names(svidf),svidf), levels=names(svidf))
As we can see, there are 11 columns listed as ‘pct without health insurance’ across 2 rows (one full row of 10, and 1 column in the next row). This is as we expect looking at our svi_pcts df where 11% of the population in the Middle Atlantic Division in 2010 were uninsured:
Now we can pause here to go save our newly created waffle_charts() function and FontAwesome icon variables to our project_data_steps.R file.
Plot Waffle Charts
Once our function is all set to go in our project_data_steps.R file, we can begin using the function to create our infographics:
var_search Keywords & icons
First, we can make a list of the var_search keywords and FA icons we need to plot our waffle charts sets:
poverty, person_icon
employ, person_icon
cost-burdened, house_icon
adults, person_icon
age, person_icon
families, parent_icon
English, person_icon
race, person_icon
housing$, house_icon
crowded, house_icon
vehicle, car_icon
group, groupqtr_icon
health, health_icon
disabled, person_icon
Note that for housing we use the grepl endswith indicator $ to avoid pulling the housing cost-burdened variables in with our housing type percentages.
Create infographics
Now that we have our 14 keyword and icon combinations, we can utilize our new function to create all of our infographics.
We will group them into our four SVI categories:
Socioeconomic Status
Household Characteristics
Racial and Ethnic Minority Status
Housing Type and Transportation
Socieconomic Status Infographics
Poverty
Code
pov<-waffle_charts(svi_pcts =svi_pcts, var_search ="poverty", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population living below 150% poverty in ", census_division, ", 2010"), title_label_usa_year1 ="Population living below 150% poverty in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population living below 150% poverty in ", census_division, ", 2020"), title_label_usa_year2 ="Population living below 150% poverty in United States, 2020", census_division =census_division)
Unemployed
Code
unemploy<-waffle_charts(svi_pcts =svi_pcts, var_search ="employ", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population unemployed in ", census_division, ", 2010"), title_label_usa_year1 ="Population unemployed in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population unemployed in ", census_division, ", 2020"), title_label_usa_year2 ="Population unemployed in United States, 2020", census_division =census_division)
Housing cost-burdened
Code
house_cost<-waffle_charts(svi_pcts =svi_pcts, var_search ="cost-burdened", fa_icon =house_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population housing cost-burdened in ", census_division, ", 2010"), title_label_usa_year1 ="Population housing cost-burdened in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population housing cost-burdened in ", census_division, ", 2020"), title_label_usa_year2 ="Population housing cost-burdened in United States, 2020", census_division =census_division)
High School Education
Code
hsed<-waffle_charts(svi_pcts =svi_pcts, var_search ="adults", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Adult education status in ", census_division, ", 2010"), title_label_usa_year1 ="Adult education status in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Adult education status in ", census_division, ", 2020"), title_label_usa_year2 ="Adult education status in United States, 2020", census_division =census_division)
Health Insurance
Code
healthins<-waffle_charts(svi_pcts =svi_pcts, var_search ="health", fa_icon =health_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population health insurance status in ", census_division, ", 2010"), title_label_usa_year1 ="Population health insurance status in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population health insurance status in ", census_division, ", 2020"), title_label_usa_year2 ="Population health insurance status in United States, 2020", census_division =census_division)
Create SES infographic, edit image
Code
# Join SES plots with patchwork package syntaxpov[[1]]/pov[[2]]/pov[[3]]/pov[[4]]/unemploy[[1]]/unemploy[[2]]/unemploy[[3]]/unemploy[[4]]/house_cost[[1]]/house_cost[[2]]/house_cost[[3]]/house_cost[[4]]/hsed[[1]]/hsed[[2]]/hsed[[3]]/hsed[[4]]/healthins[[1]]/healthins[[2]]/healthins[[3]]/healthins[[4]]
Code
# Set output locationout<-here::here(paste0("labs/wk03/imgs/infographic", "_SES", "_", str_replace_all(census_division, " ", "_"), ".png"))# Save plot as imageggsave(out, device ="png", width =1050, height=520*20, units ="px")# Load image to magick packagemagick_image=magick::image_read(out)# Trim to remove excess marginscropped_out=magick::image_trim(magick_image)# Save final cropped infographicmagick::image_write(cropped_out, path =out, format ="png")
Household Characteristics Infographics
Age
Code
age<-waffle_charts(svi_pcts =svi_pcts, var_search ="age", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Age distribution in ", census_division, ", 2010"), title_label_usa_year1 ="Age distribution in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Age distribution in ", census_division, ", 2020"), title_label_usa_year2 ="Age distribution in United States, 2020", census_division =census_division)
Disability status
Code
disabled<-waffle_charts(svi_pcts =svi_pcts, var_search ="disabled", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Civilian population with disability in ", census_division, ", 2010"), title_label_usa_year1 ="Civilian population with disability in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Civilian population with disability in ", census_division, ", 2020"), title_label_usa_year2 ="Civilian population with disability in United States, 2020", census_division =census_division)
Family Types
Code
family<-waffle_charts(svi_pcts =svi_pcts, var_search ="families", fa_icon =parent_icon, filter_year1 =2010, title_label_div_year1 =paste0("Family types in ", census_division, ", 2010"), title_label_usa_year1 ="Family types in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Family types in ", census_division, ", 2020"), title_label_usa_year2 ="Family types in United States, 2020", census_division =census_division)
Language
Code
lang<-waffle_charts(svi_pcts =svi_pcts, var_search ="English", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("English language proficiency in ", census_division, ", 2010"), title_label_usa_year1 ="English language proficiency in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("English language proficiency in ", census_division, ", 2020"), title_label_usa_year2 ="English language proficiency in United States, 2020", census_division =census_division)
# Join household characteristics plots with patchwork package syntaxage[[1]]/age[[2]]/age[[3]]/age[[4]]/disabled[[1]]/disabled[[2]]/disabled[[3]]/disabled[[4]]/family[[1]]/family[[2]]/family[[3]]/family[[4]]/lang[[1]]/lang[[2]]/lang[[3]]/lang[[4]]
Code
# Set output locationout<-here::here(paste0("labs/wk03/imgs/infographic", "_HHChar", "_", str_replace_all(census_division, " ", "_"), ".png"))# Save plot as imageggsave(out, device ="png", width =1050, height=520*16, units ="px")# Load image to magick packagemagick_image=magick::image_read(out)# Trim to remove excess marginscropped_out=magick::image_trim(magick_image)# Save final cropped infographicmagick::image_write(cropped_out, path =out, format ="png")
Racial and Ethnic Minority Status Infographics
Code
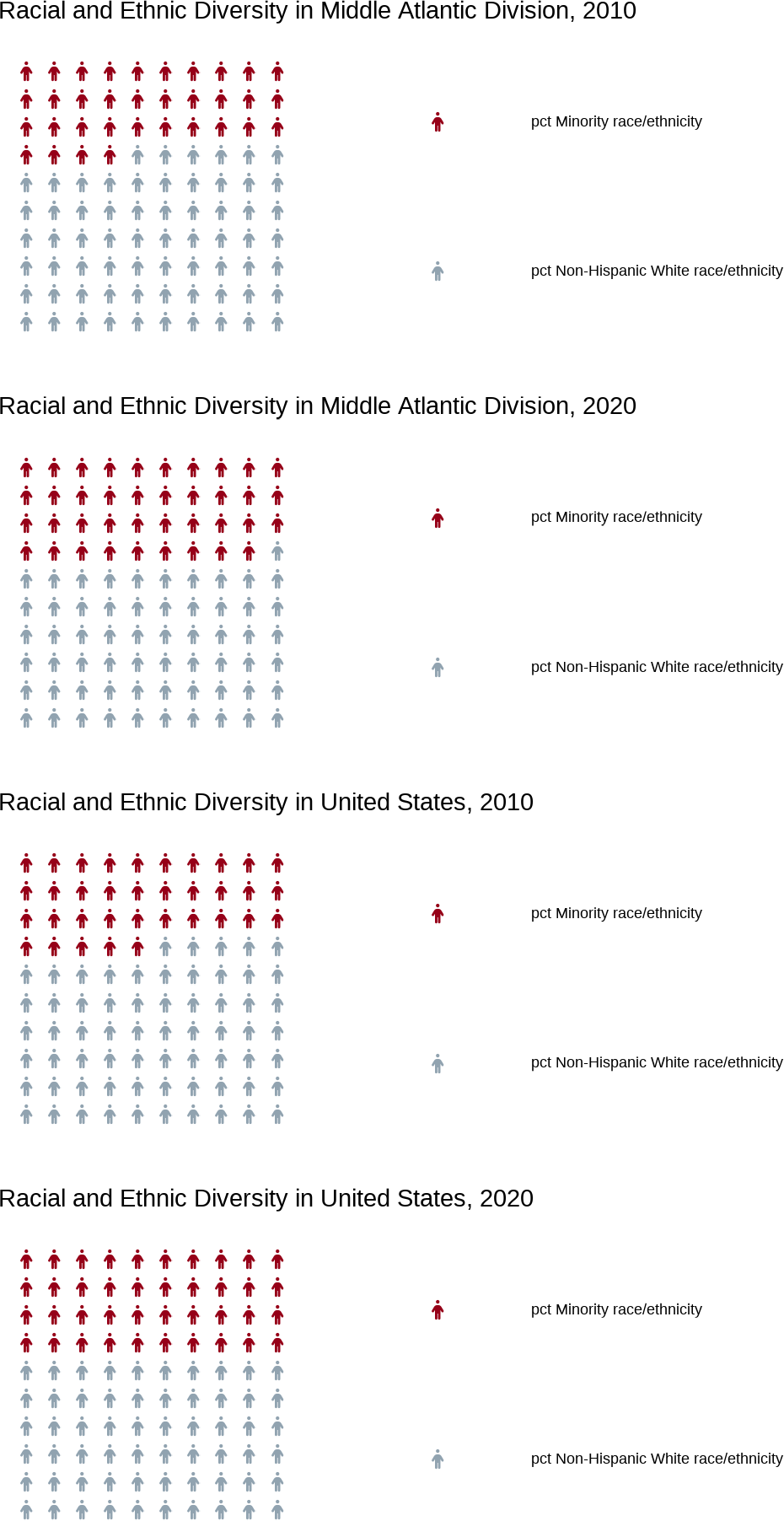
race<-waffle_charts(svi_pcts =svi_pcts, var_search ="race", fa_icon =person_icon, filter_year1 =2010, title_label_div_year1 =paste0("Racial and Ethnic Diversity in ", census_division, ", 2010"), title_label_usa_year1 ="Racial and Ethnic Diversity in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Racial and Ethnic Diversity in ", census_division, ", 2020"), title_label_usa_year2 ="Racial and Ethnic Diversity in United States, 2020", census_division =census_division)
Create Racial and Ethnic Minority infographic, edit image
Code
# Join racial and ethnic minority plots with patchwork package syntaxrace[[1]]/race[[2]]/race[[3]]/race[[4]]
Code
# Set output locationout<-here::here(paste0("labs/wk03/imgs/infographic", "_REM", "_", str_replace_all(census_division, " ", "_"), ".png"))# Save plot as imageggsave(out, device ="png", width =1050, height=520*4, units ="px")# Load image to magick packagemagick_image=magick::image_read(out)# Trim to remove excess marginscropped_out=magick::image_trim(magick_image)# Save final cropped infographicmagick::image_write(cropped_out, path =out, format ="png")
Housing Type and Transportation Infographics
Housing Types
Code
house_type<-waffle_charts(svi_pcts =svi_pcts, var_search ="housing$", fa_icon =house_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population housing types in ", census_division, ", 2010"), title_label_usa_year1 ="Population housing types in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population housing types in ", census_division, ", 2020"), title_label_usa_year2 ="Population housing types in United States, 2020", census_division =census_division)
Crowded living
Code
crowded<-waffle_charts(svi_pcts =svi_pcts, var_search ="crowded", fa_icon =house_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population living in crowded housing in ", census_division, ", 2010"), title_label_usa_year1 ="Population living in crowded housing in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population living in crowded housing in ", census_division, ", 2020"), title_label_usa_year2 ="Population living in crowded housing in United States, 2020", census_division =census_division)
Transportation access
Code
car<-waffle_charts(svi_pcts =svi_pcts, var_search ="vehicle", fa_icon =car_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population vehicle access in ", census_division, ", 2010"), title_label_usa_year1 ="Population vehicle access in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population vehicle access in ", census_division, ", 2020"), title_label_usa_year2 ="Population vehicle access in United States, 2020", census_division =census_division)
Group Quarters
Code
group<-waffle_charts(svi_pcts =svi_pcts, var_search ="group", fa_icon =groupqtr_icon, filter_year1 =2010, title_label_div_year1 =paste0("Population living in group quarters in ", census_division, ", 2010"), title_label_usa_year1 ="Population living in group quarters in United States, 2010", filter_year2 =2020, title_label_div_year2 =paste0("Population living in group quarters in ", census_division, ", 2020"), title_label_usa_year2 ="Population living in group quarters in United States, 2020", census_division =census_division)
Create Housing and Transportation infographic, edit image
Code
# Join racial and ethnic minority plots with patchwork package syntaxhouse_type[[1]]/house_type[[2]]/house_type[[3]]/house_type[[4]]/crowded[[1]]/crowded[[2]]/crowded[[3]]/crowded[[4]]/car[[1]]/car[[2]]/car[[3]]/car[[4]]/group[[1]]/group[[2]]/group[[3]]/group[[4]]
Code
# Set output locationout<-here::here(paste0("labs/wk03/imgs/infographic", "_HAT", "_", str_replace_all(census_division, " ", "_"), ".png"))# Save plot as imageggsave(out, device ="png", width =1050, height=520*16, units ="px")# Load image to magick packagemagick_image=magick::image_read(out)# Trim to remove excess marginscropped_out=magick::image_trim(magick_image)# Save final cropped infographicmagick::image_write(cropped_out, path =out, format ="png")
Check all infographics saved
We can use the following code to check all of our files saved correctly to the imgs folder (there should be 4 for your division)
Alt-text: Infographic of Racial and Ethnic Diversity
Choropleth Maps
Now that we have learned how to create Waffle Charts, let’s explore another type of infographic: choropleth maps.
As explained in the video at the beginning of this lab, choropleth maps are useful to explore variations in a topic of interest across geographical regions.
For this lab we will examine how counties across our division of interest vary in social vulnerability as measured by the total number of SVI flags per 1000 people in the population.
Download Shapefiles
In order to create our map, we will need to download shapefiles from the R library tigris. However, before let’s first define shapefiles:
What is a Shapefile?
A shapefile is a vector data file format commonly used for geospatial analysis. Shapefiles store the location, geometry, and attribution of point, line, and polygon features.
Why is a Shapefile Important?
Shapefiles are one of the most common file formats for geospatial data. They store data as points, lines, or polygons. These three feature types form the basis of geospatial vector data analysis. Points can be used to represent addresses, points of interest, and parcel or ZIP Code centroids. Lines are often used to depict road networks or waterways. Polygonal data can represent anything with a boundary, such as a neighborhood, census block, or geofence.
As explained in the Precisely glossary, shapefiles provide us with the data we need to represent geographic locations and features on a map.
The US Census Bureau provides TIGER/Line shapefiles of the United States at various geographic levels. The tigris library was created to allow for R users to easily download these files for analysis.
To begin, let’s identify the unique states in our division:
Code
# Find states in divisionstates<-svi_2020_divisional%>%select(state)%>%unique()states<-states$statestates
[1] "NJ" "NY" "PA"
Code
# Find state FIPS codesstate_fips<-fips_census_regions%>%filter(division==census_division)%>%select(state_code)%>%unique()state_fips<-state_fips$state_codestate_fips
[1] "34" "36" "42"
Next, we can pull the state-level shapefiles from the tigris package:
Code
# Recall that we are working with 2010 census tracts, thus we need to pull the 2010 shapefilesst_sf<-tigris::states(year =2010, cb =TRUE)%>%filter(STATE%in%state_fips)# Shift geometric locations of AK and HI if Pacific divisionif(census_division=="Pacific Division"){st_sf<-shift_geometry(st_sf, geoid_column =NULL, preserve_area =FALSE, position =c("below", "outside"))}else{st_sf<-st_sf}
Code
# View datast_sf
Simple feature collection with 3 features and 5 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -80.51989 ymin: 38.92852 xmax: -71.85621 ymax: 45.01585
Geodetic CRS: NAD83
GEO_ID STATE NAME LSAD CENSUSAREA geometry
1 0400000US34 34 New Jersey <NA> 7354.22 MULTIPOLYGON (((-75.52684 3...
2 0400000US36 36 New York <NA> 47126.40 MULTIPOLYGON (((-71.94356 4...
3 0400000US42 42 Pennsylvania <NA> 44742.70 MULTIPOLYGON (((-75.41504 3...
Finally we need to pull county-level shapefiles from the tigris package:
Code
# Recall that we are working with 2010 census tracts, thus we need to pull the 2010 shapefilescounty_sf=tigris::counties(year =2010, cb =TRUE)%>%filter(STATE%in%state_fips)# Shift geometric locations of AK and HI if Pacific divisionif(census_division=="Pacific Division"){county_sf<-shift_geometry(county_sf, geoid_column =NULL, preserve_area =FALSE, position =c("below", "outside"))}else{county_sf<-county_sf}
Code
# View datacounty_sf
Simple feature collection with 150 features and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -80.51989 ymin: 38.92852 xmax: -71.85621 ymax: 45.01585
Geodetic CRS: NAD83
First 10 features:
GEO_ID STATE COUNTY NAME LSAD CENSUSAREA
1 0500000US34001 34 001 Atlantic County 555.704
2 0500000US34003 34 003 Bergen County 233.009
3 0500000US34005 34 005 Burlington County 798.576
4 0500000US34007 34 007 Camden County 221.263
5 0500000US34009 34 009 Cape May County 251.425
6 0500000US34011 34 011 Cumberland County 483.703
7 0500000US34013 34 013 Essex County 126.212
8 0500000US34015 34 015 Gloucester County 322.005
9 0500000US34017 34 017 Hudson County 46.191
10 0500000US34019 34 019 Hunterdon County 427.819
geometry COUNTYFP STATEFP
1 MULTIPOLYGON (((-74.42314 3... 001 34
2 MULTIPOLYGON (((-73.92676 4... 003 34
3 MULTIPOLYGON (((-74.99056 4... 005 34
4 MULTIPOLYGON (((-75.14001 3... 007 34
5 MULTIPOLYGON (((-74.94545 3... 009 34
6 MULTIPOLYGON (((-75.1145 39... 011 34
7 MULTIPOLYGON (((-74.13892 4... 013 34
8 MULTIPOLYGON (((-75.20008 3... 015 34
9 MULTIPOLYGON (((-74.02039 4... 017 34
10 MULTIPOLYGON (((-75.19491 4... 019 34
View shapefiles
Before we add our data, let’s take a look at our downloaded shapefiles as a map. We can use the ggplot2 package and its interactive extension ggiraph for mapping:
As we can see, the state-level shapefile provide the outer boundary lines for our states while the county-level shapefile breaks down the boundaries to individual states. The tigris package has a variety of boundary levels that you can explore by visiting the package’s Github repo here: https://github.com/walkerke/tigris
Prepare map data
Now we need to summarize our Social Vulnerability Index (SVI) flag data by county within our states for 2010 and 2020.
We can create a function to do this (and place it in our project_data_steps.R file):
Code
flag_summarize<-function(df, pop_var){df_flags<-df%>%filter(!is.na(F_TOTAL))%>%group_by(FIPS_st, FIPS_county)%>%mutate(flag_count =sum(F_TOTAL), pop =sum(!!as.name(pop_var)), flag_by_pop =flag_count/pop)%>%select(FIPS_st, FIPS_county, state, state_name, county, region_number, region, division_number, division, flag_count, pop, flag_by_pop)%>%unique()# Assign counts to quantilesdf_flags<-df_flags%>%mutate( flag_count_quantile =cut(flag_count,quantile(df_flags$flag_count, probs =seq(0, 1, .2)),include.lowest=TRUE,labels=FALSE), flag_pop_quantile =cut(flag_by_pop,quantile(df_flags$flag_by_pop, probs =seq(0, 1, .2)),include.lowest=TRUE,labels=FALSE))%>%# Convert quantiles to ratios from .20 - 1mutate(flag_count_quantile =case_when(flag_count_quantile==1~.20,flag_count_quantile==2~.40,flag_count_quantile==3~.60,flag_count_quantile==4~.80,flag_count_quantile==5~1))%>%# Convert quantiles to ratios from .20 - 1mutate(flag_pop_quantile =case_when(flag_pop_quantile==1~.20,flag_pop_quantile==2~.40,flag_pop_quantile==3~.60,flag_pop_quantile==4~.80,flag_pop_quantile==5~1))return(df_flags)}
2010 SVI Flag data
Code
# Summarize total count of flags by state and countycounty_svi_flags10<-flag_summarize(svi_2010_divisional, "E_TOTPOP_10")# View datacounty_svi_flags10%>%head()%>%kbl()%>%kable_styling()%>%scroll_box(width ="100%")
FIPS_st
FIPS_county
state
state_name
county
region_number
region
division_number
division
flag_count
pop
flag_by_pop
flag_count_quantile
flag_pop_quantile
34
001
NJ
New Jersey
Atlantic County
1
Northeast Region
2
Middle Atlantic Division
317
264511
0.0011984
1.0
1.0
34
003
NJ
New Jersey
Bergen County
1
Northeast Region
2
Middle Atlantic Division
436
896482
0.0004863
1.0
0.2
34
005
NJ
New Jersey
Burlington County
1
Northeast Region
2
Middle Atlantic Division
241
447861
0.0005381
0.8
0.2
34
007
NJ
New Jersey
Camden County
1
Northeast Region
2
Middle Atlantic Division
463
513574
0.0009015
1.0
0.8
34
009
NJ
New Jersey
Cape May County
1
Northeast Region
2
Middle Atlantic Division
99
97684
0.0010135
0.6
1.0
34
011
NJ
New Jersey
Cumberland County
1
Northeast Region
2
Middle Atlantic Division
179
148233
0.0012076
0.8
1.0
Code
# View flag count quartilescounty_svi_flags10$flag_count_quantile%>%unique()%>%sort()
[1] 0.2 0.4 0.6 0.8 1.0
2020 SVI Flag data
Code
# Summarize total count of flags by state and countycounty_svi_flags20<-flag_summarize(svi_2020_divisional, "E_TOTPOP_20")# View datacounty_svi_flags20%>%head()%>%kbl()%>%kable_styling()%>%scroll_box(width ="100%")
FIPS_st
FIPS_county
state
state_name
county
region_number
region
division_number
division
flag_count
pop
flag_by_pop
flag_count_quantile
flag_pop_quantile
34
001
NJ
New Jersey
Atlantic County
1
Northeast Region
2
Middle Atlantic Division
335
264649
0.0012658
1.0
1.0
34
003
NJ
New Jersey
Bergen County
1
Northeast Region
2
Middle Atlantic Division
454
931264
0.0004875
1.0
0.2
34
005
NJ
New Jersey
Burlington County
1
Northeast Region
2
Middle Atlantic Division
237
446295
0.0005310
0.8
0.2
34
007
NJ
New Jersey
Camden County
1
Northeast Region
2
Middle Atlantic Division
463
506715
0.0009137
1.0
0.8
34
009
NJ
New Jersey
Cape May County
1
Northeast Region
2
Middle Atlantic Division
84
92701
0.0009061
0.6
0.8
34
011
NJ
New Jersey
Cumberland County
1
Northeast Region
2
Middle Atlantic Division
181
140953
0.0012841
0.8
1.0
Create Interactive Tooltips
As mentioned above, we can use the ggiraph package to create an interactive HTML map. This means that when we generate our map, we will be able to hover over our counties and have a popup appear with specific information about each segment of the map. This popup is called a tooltip. Thus, we need to add a column for the tooltip to our data frame.
We can create a new function for this (and add it it our project_data_steps.R file):
Code
# Note that "\n" indicates a line break in HTML and will place the elements on different lines of our tooltip# htmltools::htmlEscape(df$county, TRUE) encodes any special characters county names for HTMLmap_tooltip<-function(df){df$flag_pop_quantile_pct<-scales::percent(df$flag_pop_quantile, accuracy =1)df$tooltip<-paste0(htmltools::htmlEscape(df$county, TRUE), ", ", df$state, "\n", "SVI Flags: ", prettyNum(df$flag_count, big.mark =",", scientific =FALSE), "\n", "County Population: ", prettyNum(df$pop, big.mark =",", scientific =FALSE), "\n", "SVI-Flag-to-Population Ratio (per 1,000): ", (round(df$flag_by_pop, 6)*1000), "\n","Quintile: ", df$flag_pop_quantile_pct)return(df)}
Simple feature collection with 150 features and 22 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -80.51989 ymin: 38.92852 xmax: -71.85621 ymax: 45.01585
Geodetic CRS: NAD83
First 10 features:
GEO_ID STATE COUNTY NAME LSAD CENSUSAREA COUNTYFP STATEFP
1 0500000US34001 34 001 Atlantic County 555.704 001 34
2 0500000US34003 34 003 Bergen County 233.009 003 34
3 0500000US34005 34 005 Burlington County 798.576 005 34
4 0500000US34007 34 007 Camden County 221.263 007 34
5 0500000US34009 34 009 Cape May County 251.425 009 34
6 0500000US34011 34 011 Cumberland County 483.703 011 34
7 0500000US34013 34 013 Essex County 126.212 013 34
8 0500000US34015 34 015 Gloucester County 322.005 015 34
9 0500000US34017 34 017 Hudson County 46.191 017 34
10 0500000US34019 34 019 Hunterdon County 427.819 019 34
state state_name county region_number region
1 NJ New Jersey Atlantic County 1 Northeast Region
2 NJ New Jersey Bergen County 1 Northeast Region
3 NJ New Jersey Burlington County 1 Northeast Region
4 NJ New Jersey Camden County 1 Northeast Region
5 NJ New Jersey Cape May County 1 Northeast Region
6 NJ New Jersey Cumberland County 1 Northeast Region
7 NJ New Jersey Essex County 1 Northeast Region
8 NJ New Jersey Gloucester County 1 Northeast Region
9 NJ New Jersey Hudson County 1 Northeast Region
10 NJ New Jersey Hunterdon County 1 Northeast Region
division_number division flag_count pop flag_by_pop
1 2 Middle Atlantic Division 335 264649 0.0012658276
2 2 Middle Atlantic Division 454 931264 0.0004875094
3 2 Middle Atlantic Division 237 446295 0.0005310389
4 2 Middle Atlantic Division 463 506715 0.0009137286
5 2 Middle Atlantic Division 84 92701 0.0009061391
6 2 Middle Atlantic Division 181 140953 0.0012841160
7 2 Middle Atlantic Division 1392 796608 0.0017474090
8 2 Middle Atlantic Division 110 291749 0.0003770364
9 2 Middle Atlantic Division 1044 671928 0.0015537379
10 2 Middle Atlantic Division 32 125063 0.0002558710
flag_count_quantile flag_pop_quantile flag_pop_quantile_pct
1 1.0 1.0 100%
2 1.0 0.2 20%
3 0.8 0.2 20%
4 1.0 0.8 80%
5 0.6 0.8 80%
6 0.8 1.0 100%
7 1.0 1.0 100%
8 0.6 0.2 20%
9 1.0 1.0 100%
10 0.2 0.2 20%
tooltip
1 Atlantic County, NJ\nSVI Flags: 335\nCounty Population: 264,649\nSVI-Flag-to-Population Ratio (per 1,000): 1.266\nQuintile: 100%
2 Bergen County, NJ\nSVI Flags: 454\nCounty Population: 931,264\nSVI-Flag-to-Population Ratio (per 1,000): 0.488\nQuintile: 20%
3 Burlington County, NJ\nSVI Flags: 237\nCounty Population: 446,295\nSVI-Flag-to-Population Ratio (per 1,000): 0.531\nQuintile: 20%
4 Camden County, NJ\nSVI Flags: 463\nCounty Population: 506,715\nSVI-Flag-to-Population Ratio (per 1,000): 0.914\nQuintile: 80%
5 Cape May County, NJ\nSVI Flags: 84\nCounty Population: 92,701\nSVI-Flag-to-Population Ratio (per 1,000): 0.906\nQuintile: 80%
6 Cumberland County, NJ\nSVI Flags: 181\nCounty Population: 140,953\nSVI-Flag-to-Population Ratio (per 1,000): 1.284\nQuintile: 100%
7 Essex County, NJ\nSVI Flags: 1,392\nCounty Population: 796,608\nSVI-Flag-to-Population Ratio (per 1,000): 1.747\nQuintile: 100%
8 Gloucester County, NJ\nSVI Flags: 110\nCounty Population: 291,749\nSVI-Flag-to-Population Ratio (per 1,000): 0.377\nQuintile: 20%
9 Hudson County, NJ\nSVI Flags: 1,044\nCounty Population: 671,928\nSVI-Flag-to-Population Ratio (per 1,000): 1.554\nQuintile: 100%
10 Hunterdon County, NJ\nSVI Flags: 32\nCounty Population: 125,063\nSVI-Flag-to-Population Ratio (per 1,000): 0.256\nQuintile: 20%
geometry
1 MULTIPOLYGON (((-74.42314 3...
2 MULTIPOLYGON (((-73.92676 4...
3 MULTIPOLYGON (((-74.99056 4...
4 MULTIPOLYGON (((-75.14001 3...
5 MULTIPOLYGON (((-74.94545 3...
6 MULTIPOLYGON (((-75.1145 39...
7 MULTIPOLYGON (((-74.13892 4...
8 MULTIPOLYGON (((-75.20008 3...
9 MULTIPOLYGON (((-74.02039 4...
10 MULTIPOLYGON (((-75.19491 4...
Plot Choropleth Maps
Finally, we can create a function to plot our maps (REMEMBER you will want this function in your project_data_steps.R file):
Code
choropleth_map<-function(df, fill_var, year_var){gg_int<-ggplot()+# Make theme empty for customizationtheme_void()+# Set color palettescale_fill_gradient2(low ="#B9D9EB", high="#003262", labels =scales::label_percent())+# Load interactive shapefile layer with county datageom_sf_interactive(data=df , aes(geometry=geometry, fill=!!as.name(fill_var), tooltip =tooltip, data_id =tooltip), size =0.1)+# Load overall state outlines from state shapefiles, can update linewidth thickness to highlight outlines depending on size/spacing of states, .5 - 1.5 is usually a good rangegeom_sf(data=st_sf, color="white", fill=NA, linewidth=.5, aes(geometry=geometry))+labs(title=paste0(year_var, " SVI Flag to Population Ratio", "\U2014", census_division), fill="Quintile")return(gg_int)}
# Save map to HTML file for embedding in final project save_int<-girafe(ggobj =gg_int10)setwd(here::here("labs/wk03/imgs"))htmlwidgets::saveWidget(widgetframe::frameableWidget(save_int), here::here(paste0("labs/wk03/imgs/", "flag_pop_quantile", "2010", "_", str_replace_all(census_division, " ", "_"), "map.html")))setwd(here::here("labs/wk03/"))
# Save map to HTML file for embedding in final project save_int<-girafe(ggobj =gg_int20)setwd(here::here("labs/wk03/imgs"))htmlwidgets::saveWidget(widgetframe::frameableWidget(save_int),here::here(paste0("labs/wk03/imgs/", "flag_pop_quantile", "2020", "_", str_replace_all(census_division, " ", "_"), "map.html")))setwd(here::here("labs/wk03/"))
As a final observation, you may be curious why we’re mapping the flag-to-population ratio instead of the flag count.
This is because our SVI flags are summed to the county level from census tracts. Census tracts can vary in size and larger counties have more census tracts. Thus when counties are larger they are more likely to have more SVI flags than smaller counties and can falsely appear to be at higher risk. To adjust for this, we can divide our flag count by the county population and then multiply this by 1,000 to get a ratio of flag-to-population per 1,000 people. This provides us with an equitable comparison across counties of varying sizes.
To visualize this, let’s look at a map of the 2020 data for flag_count:
Code
gg_int_cnt20<-ggplot()+# Make theme empty for customizationtheme_void()+# Set color palettescale_fill_gradient2(low ="#B9D9EB", high="#003262", labels =scales::label_percent())+# Load interactive shapefile layer with county datageom_sf_interactive(data=county_svi_flags20 , aes(geometry=geometry, fill=flag_count_quantile, tooltip =tooltip, data_id =tooltip), size =0.1)+# Load overall state outlines from state shapefilesgeom_sf(data=st_sf, color="white", fill=NA, linewidth=.5, aes(geometry=geometry))+labs(title=paste0("2020", " SVI Flag Count—", census_division), fill="Quintile")girafe(ggobj =gg_int_cnt20)
Here we can see that all of the areas that are highlighted as most vulnerable are large population centers consisting of the counties that make up cities such as Pittsburgh, PA (Allegheny County), Philadelphia, PA (Philadelphia County), Newark, NJ (Essex County), and the counties associated with the five boroughs of New York City (Bronx County, Kings County (Brooklyn), New York County (Manhattan), Queens County, Richmond County (Staten Island)).
While there is some overlap with our population-adjusted maps (largely due to the fact that urban areas often are subject to social vulnerability), we can also see that there are several smaller counties on the map that are not properly identified as being vulnerable for their population size.
Therefore, we will omit graphing the raw flags count.
Check all visuals saved
Finally we can see all of the infographics we’ve saved:
You can also use the following code to embed your infographic images in your final file (Replace Middle_Atlantic_Division with your Census Division:



Note
Your import step in your .RMD file should look similar to the code chunk below, but your project_data_steps.R file should have your initials on the end (i.e. project_data_steps_CS.R).
Code
import::here("fips_census_regions","load_svi_data","merge_svi_data","census_division","svi_percentages10","svi_percentages20","waffle_charts","person_icon","house_icon","car_icon","parent_icon","health_icon","groupqtr_icon","flag_summarize","map_tooltip","choropleth_map",# notice the use of here::here() that points to the .R file# where all these R objects are created .from =here::here("analysis/project_data_steps.R"), .character_only =TRUE)
The following checklist will ensure that you’re on track: